Issues





Issue 48
September 2011
- Issue 48
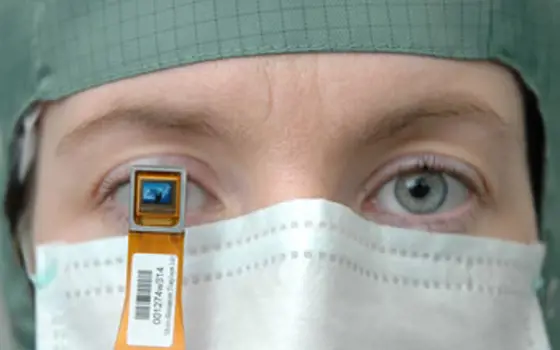
Computer Vision Advances
- Issue 48
Constructing the Hindhead Tunnel
- Issue 48
Facial Recognition
- Issue 48
Innovation Watch - Helping Buildings Breathe
- Issue 48
Industrial Systems – the vital role of manufacturing
- Issue 48
Sir John Parker FREng - Engineering Success
- Issue 48
Tattoo's New Grandstand
- Issue 48